similar to Subspace Sampling and Bagging
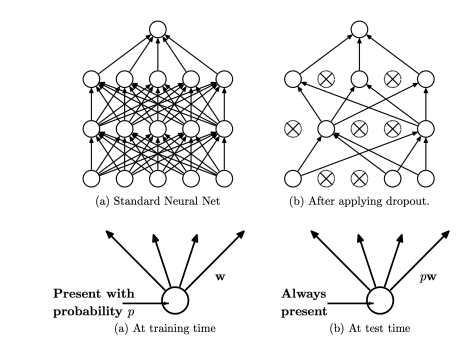
- During each training step (i.e., gradient update step), a fraction (typically half) of the units in specified hidden layers are “dropped”. Thus, only the weights and biases related to units that are not dropped are updated in this gradient step
- During test, the entire network is used after scaling the weights based on the dropout rate
- prevents co-adaptation among different neurons
Dilution
Randomly remove weights. Dropout is a special case of dilution where we remove a whole row wj in the vector matrix W with some probability p instead of individual weights wij