Discerning relationships amongst named entities in piece of text.
Based on the domain, identify predefined types of relationships
- affiliations - personal, organizational, artifactual
- geospatial - proximity, directional
- part-of
Approaches
- pattern based
- regular expressions (regex) based
- statistical/ML
Pattern based relation extraction
Regex based
- unsupervised
- example: extract airline- hub cities relations in some text using regex
- / * has a hub at * /
- causes false positives/ low precision - matches from different types of entities than desired, i.e. not airlines
- /[ Organisation ] has a hub at [ location] /
- better, but causes false negatives - might still miss regex that’s not an exact match
- maybe relax the regex pattern (might increase FP, or lower precision) or
- expand set of patterns (reduce false negatives while keeping precision)
- better, but causes false negatives - might still miss regex that’s not an exact match
- / * has a hub at * /
- Bootstrapping in Pattern-Based Relation Extraction
- Another method → dependency paths can be used
precision & recall
precision = TP/ (TP + FP)
recall = TP/ (TP + FN)
precision : fraction of annotated items that are correct
recall : fraction of correct items that are annotated
Link to original
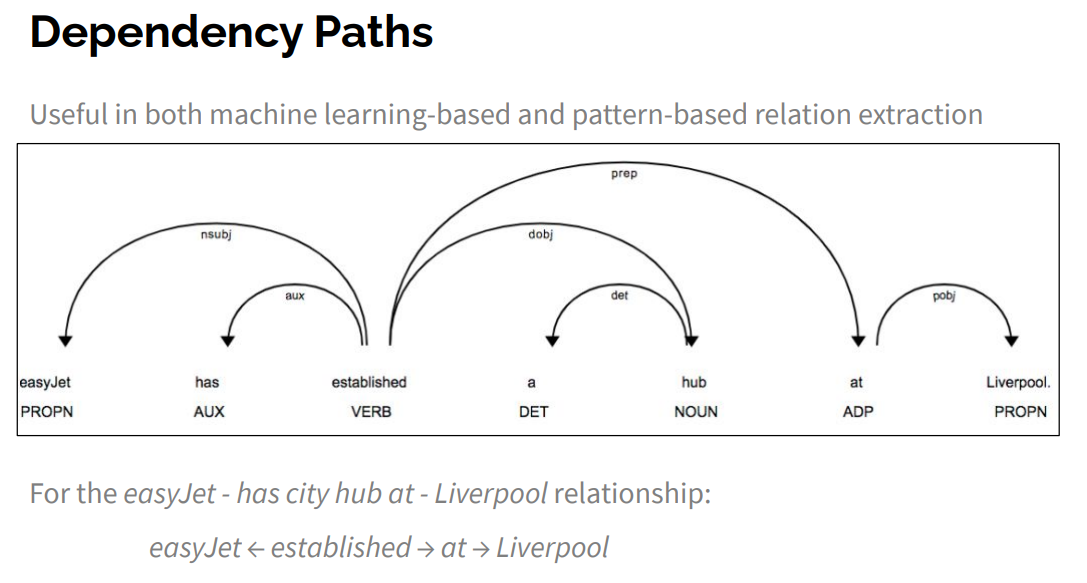
see also: Dependency Structure Parsing
Statistical /ML based relation extraction
-
usually supervised
- needs labelled data
-
2 subtasks
- detecting if a relationship exists between 2 entities
- binary classification
- classifying the relationship if it exists
- multi class classification
- detecting if a relationship exists between 2 entities
-
possible features to look at
- Lexical Features: These include the words or tokens present between two entities, the words surrounding the entities, and potentially the bag of words encompassing the context of the entities, entity type, head word
- Syntactic Features: Part-of-speech tags, dependency parse trees, and other grammatical structures provide syntactic context that can help in identifying relations
- Shortest Dependency Path: Extract the shortest path between the two entities in the dependency tree.
- Dependency Relations: Include the types of dependency relations along the path.
- Directionality: Determine the direction of the relations (e.g., subject, object) along the path.
- Subtree Features:
- Common Ancestor: Identify the lowest common ancestor of the two entities.
- Subtree Paths: Extract paths from each entity to their common ancestor.
- Graph-Based Features:
- Graph Walks: Traverse the dependency graph to capture sequential relationships between words.
- Node Properties: Include node attributes like part-of-speech tags or word embeddings.
- Semantic Features: The types of entities involved (e.g., person, organization, location) and their semantic roles within the sentence can significantly enhance the model’s ability to correctly classify relation
- context: words between, words before the first entity, words after the second entity (within a fixed window)
- semantic indexing and disambiguating entity senses → Word-Sense Disambiguation
- Word Embeddings
-
Deep learning based