- composed of perceptions
- can theoretically compute any function
- why not boolean circuits?
- differentiable end to end
Perceptron
if the activation is sigmoid, then this perceptron is basically just Logistic RegressionPerceptron
⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠
Text Elements
Link to original
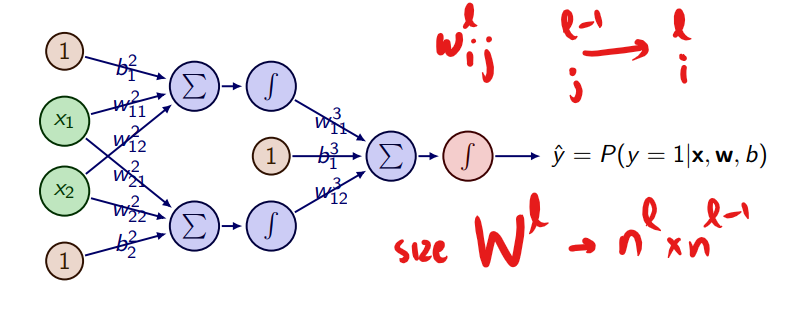
One Layer Net
activation function on a linear(affine in general) transformation There are many possible Activation Functions
A one layer net with ReLU activation would be N ∶ Rn → Rp x ↦ max{0,Wx + b} ∶= N(x)
Multi-layer Perceptron (MLP)
- multiple layer neural network, could be any kind of artificial neurons, not just perceptrons
Feedforward neural Networks
stack of multiple MLPs with multiple hidden layers
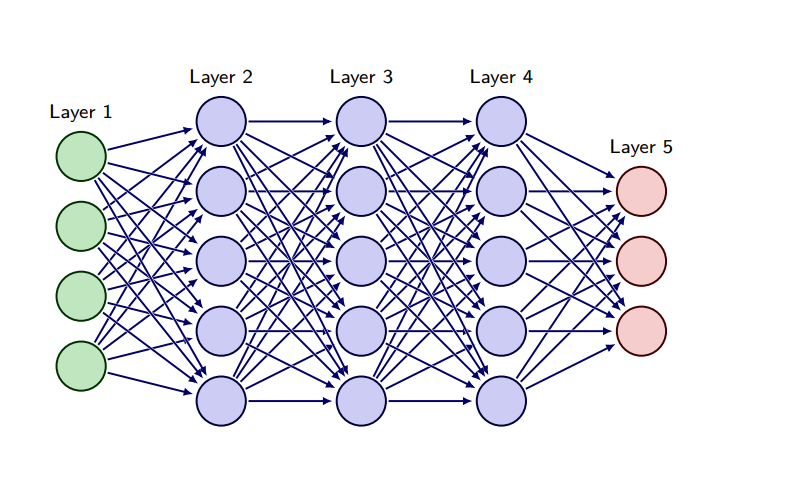
- depth = no of transformations = no of layers(counting both and input and output as layers) - 1 = 4
- max number of nodes in a layer is called the width = 5
- no of parameters = Nl * (Nl-1 +1) + Nl-1 * (Nl-2 +1) + …
- +1 accounting for bias terms, assume a bias term in every unit
deep neural nets are just functions

Population Risk and Empirical Risk
For a distribution D, a finite set of samples from it S,
Population Risk (LD) : Measures The Expected Prediction Error of N Over All Data. Empirical population risk will be over the test samples.
Empirical Risk (LS): Measures The Expected Prediction Error of N Over The Seen Training Data

Backpropagation
Backpropagation
⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠
Text Elements
Link to original
Issues with training neural networks
Neural Networks as universal approximators
In theory, one hidden layer is enough: 2 layer neural networks are universal approximators (they are capable of approximating any continuous function to any desired degree of accuracy